


撰文:Jeffrey Hu、Arnav Pagidyala
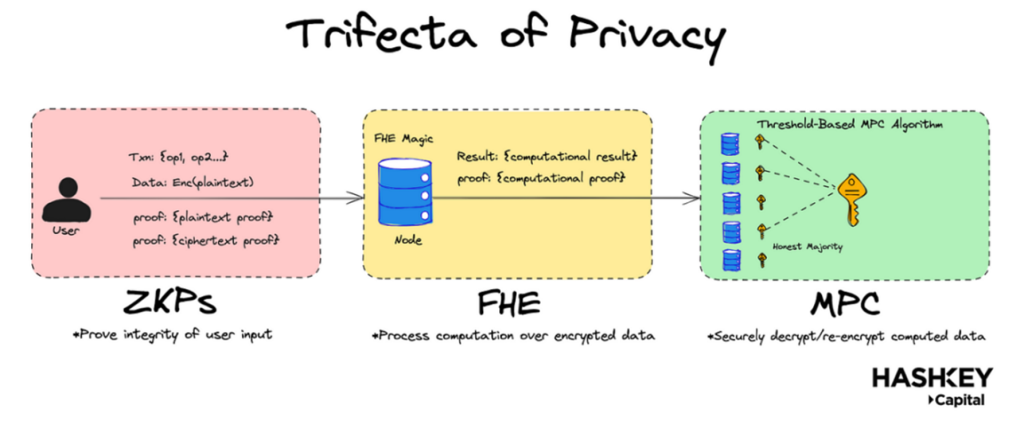
核心觀點:
- 全同態加密(FHE)被譽為「密碼學的聖杯」,但目前其應用受到性能、開發體驗和安全性方面的限制。
- 如上圖所示,為了構建一個真正保密且安全的共用狀態系統,需要將 FHE 與零知識證明(ZKPs)和多方計算(MPC)結合使用。
- FHE 正在迅速發展;新的編譯器、庫、硬體等的開發,以及 Web2 公司(如英特爾、穀歌、DARPA 等)的研發大大促進了 FHE 的發展。
- 隨著 FHE 及其周邊生態系統的成熟,我們預計「可驗證的 FHE」將成為標準。去中心化應用程式(DApps)/rollups 可能選擇將計算和驗證外包給 FHE 輔助處理器。
- 鏈上 FHE 的一個基本限制是「誰持有解密金鑰」。閾值解密(Threshold decryption)和 MPC 提供了針對這種限制的解決方案,但它們通常有需要在性能與安全性之間權衡的問題。
引言:
區塊鏈的透明性是一把雙刃劍。雖然其開放性和可觀察性很有吸引力,但這也恰恰是企業採用區塊鏈技術時的顧慮所在。
鏈上隱私一直是加密領域近十年來最具挑戰性的問題之一。儘管有許多團隊正在構建基於零知識證明(ZKP)的系統來實現鏈上隱私;但它們無法支援共用的加密狀態。原因在於這些方案是一系列 ZKP 的函數,因此不可能對當前狀態應用任意邏輯。這意味著我們不能僅僅使用 ZKP 來構建加密的共用狀態應用程式(比如私有的 Uniswap)。
然而,最近的技術突破表明,將 ZKP 與全同態加密(FHE)相結合,可以實現完全通用化、加密的去中心化金融(DeFi)。這是如何實現的呢?FHE 是一個新興的密碼學領域,能夠在加密資料上進行任意計算。如上圖所示,ZKP 可以證明用戶輸入和計算的完整性,而 FHE 可以處理計算本身。
雖然 FHE 被譽為「密碼學的聖杯」,我們將試圖提供對該領域及其各種挑戰及可能解決方案的客觀分析。該技術報告將涵蓋以下鏈上 FHE 主題:
- FHE 方案、庫和編譯器(FHE Schemes, Libraries and Compilers)
- 安全閾值解密(Secure Threshold Decryption)
- 用戶輸入和計算方的 ZKP(ZKPs for User Inputs + Computing Party)
- 可程式設計、可擴展的資料可用性(DA)層(Programmable, Scalable DA Layer)
- FHE 硬體(FHE Hardware)
全同態加密(FHE)方案、庫和編譯器
挑戰:新興的 FHE 方案、庫和編譯器
鏈上 FHE 的基本瓶頸在於其開發工具和基礎設施的滯後。與零知識證明(ZKP)或多方計算(MPC)不同,FHE 自 2009 年以來發展時間較短,因此成熟度較低。
FHE 開發體驗的主要限制包括:
- 缺少易於使用的前端語言,讓開發者在不需要深入瞭解後端密碼學的情況下進行編碼。
- 缺少功能齊全的 FHE 編譯器,能夠處理所有複雜的工作(如參數選擇、BGV/BFV 的 SIMD 優化和並行優化)。
- 現有的 FHE 方案(特別是 TFHE)與普通計算相比大約慢 1000 倍。
為了真正理解整合 FHE 的複雜性,讓我們來看一下開發者所要經歷的流程:
將 FHE 整合到應用程式中的第一步是選擇一個 FHE 方案。下表解釋了主要的方案:
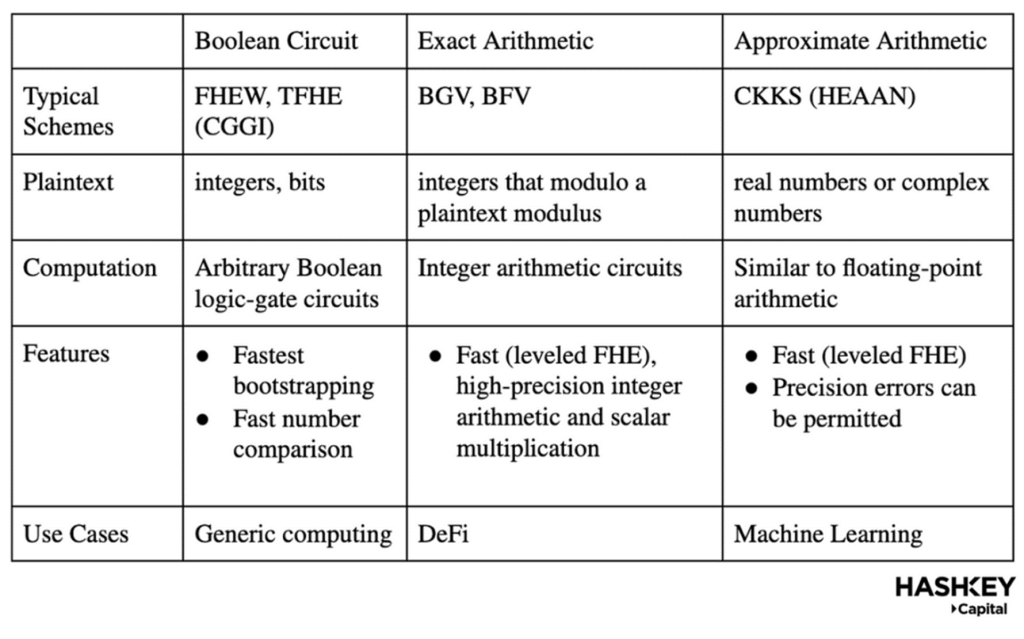
如上表所示,布林電路(如 FHEW 和 TFHE)具有最快的 bootstrapping 速度,可以避免複雜的參數選擇過程,並且可以用於任意 / 通用計算,但相對較慢;而 BGV/BFV 適合一般 DeFi 應用,因為它們在高精度算術計算方面更高效,但開發者必須提前知道電路的深度以設置 scheme 的所有參數。另一方面,CKKS 支援同態乘法,允許精度誤差,使其適用於非精確用例,如機器學習。
作為開發者,你需要非常謹慎地選擇一個 FHE 方案,因為它將影響所有其他設計決策和未來的性能。此外,還有幾個關鍵參數對於正確設置 FHE 方案至關重要,例如模數大小的選擇和多項式次數的作用。
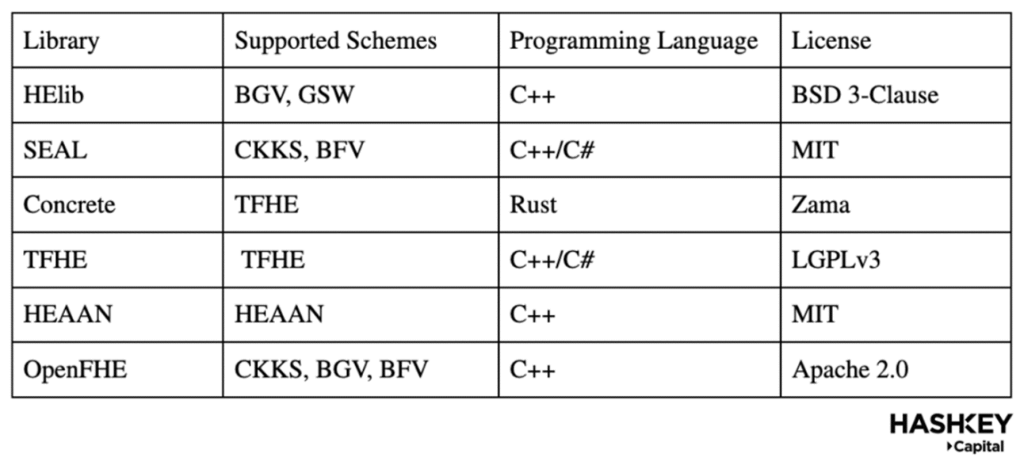
接下來我們討論庫,下表展示了目前使用較多的 FHE 庫的功能和能力:
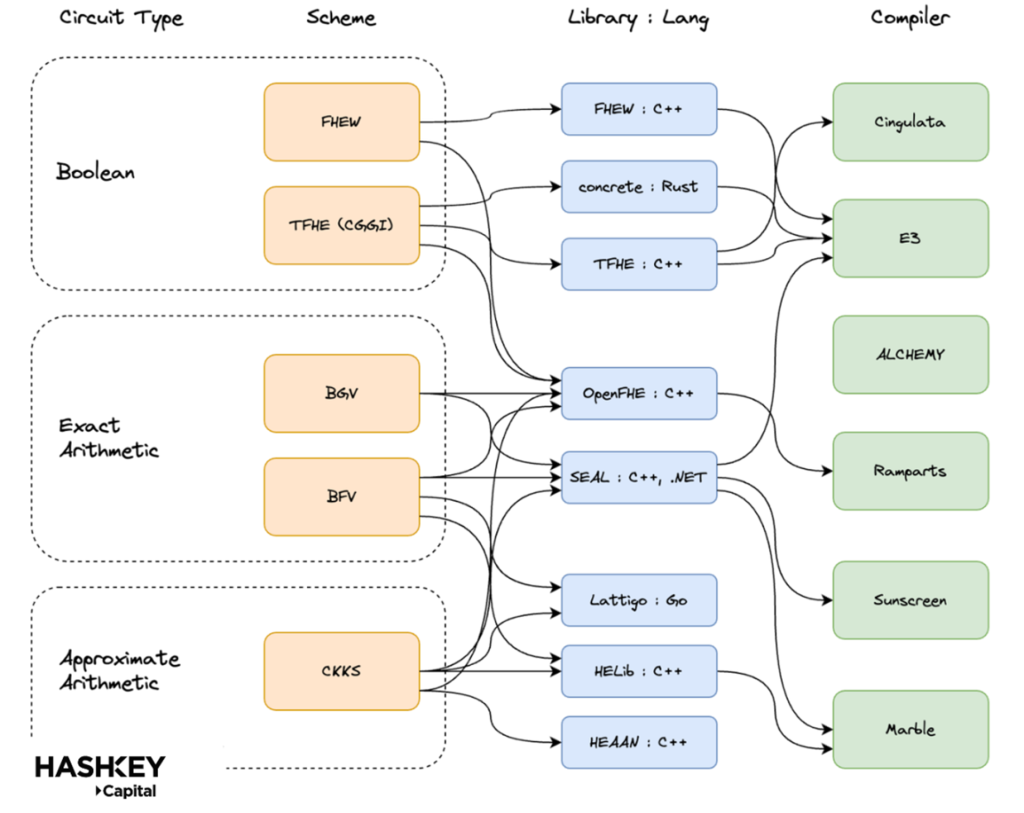
但是,這些庫與不同的 FHE 方案和編譯器的關係也各不相同,如下所示:
選擇了 FHE 方案後,開發者需要設置參數。正確選擇參數將對 FHE 方案的性能產生巨大影響。比較困難的是,這需要對抽象代數、FHE 特定操作(如重新線性化和模數切換)以及算術或二進位電路有所瞭解。最後,為了有效選擇參數,需要從概念上理解它們如何影響 FHE 方案。
此時,開發者可能會問:
我的明文(plaintext)空間需要多大?可以接受多大的密文?我在哪裡可以平行計算?等等問題……
此外,儘管 FHE 可以支援任意計算,但開發者在編寫 FHE 程式時需要改變思維方式。例如,程式中不能根據變數寫一個分支(if-else),因為程式不能將變數視為普通資料進行直接比較。相反,開發者需要將代碼從分支改為可以包含所有分支條件的某種計算。同樣,這也阻止了開發者在代碼中編寫迴圈。
簡而言之,對於不熟悉 FHE 的開發者來說,將 FHE 整合到他們的應用程式中幾乎是不可能的。這將需要顯著的開發工具和基礎設施來抽象化 FHE 所呈現的複雜性。
解決方案:
1. Web3 特定的 FHE 編譯器
雖然已經存在由穀歌和微軟等公司構建的 FHE 編譯器,但它們:
- 沒有以性能為設計目標,與直接編寫電路相比增加了 1000 倍的「開銷」
- 為 CKKS(即 ML)優化,對於 DeFi 所需的 BFV/BGV 並不那麼有益
- 不是為 Web3 構建的。不支援與 ZKP 方案、可程式設計區塊鏈等的相容性。
直到 Sunscreen FHE 編譯器的出現。它是一個 Web3 原生編譯器,為算術操作(例如 DeFi)提供了一些最佳性能,而不需要硬體加速器。如上所述,參數選擇可能是實施 FHE 方案最困難的部分。Sunscreen 不僅自動化了參數選擇,還實現了資料編碼、金鑰選擇、實施重新線性化和模數切換、設置電路和實現 SIMD 操作。
隨著技術的不斷進步,我們期待看到不僅在 Sunscreen 編譯器中,還有其他團隊構建屬於自己的,能夠支援其他高階語言的進一步優化。
2. 新的 FHE 庫
雖然研究人員不斷探索新的有效方案,但 FHE 庫也可以使更多開發者整合 FHE。
以 FHE 智能合約為例。儘管從不同的 FHE 庫中進行選擇可能很困難,但當我們談論鏈上 FHE 時,選擇就變得更容易了,因為在 Web3 中只有少數幾種主導程式設計語言。
例如,Zama 的 fhEVM 將 Zama 的開源庫 TFHE-rs 整合到典型的 EVM 中,將同態操作作為預編譯合約公開。有效地使開發者能夠在他們的合約中使用加密資料,而無需對編譯工具進行任何更改。
而對於其他特定場景,可能還需要一些其他基礎設施。例如,用 C++ 編寫的 TFHE 庫維護得不如 Rust 版本好。儘管 TFHE-rs 可以支援 C/C++ 的匯出,但如果 C++ 開發者想要更好的相容性和性能,他們必須編寫自己的 TFHE 庫版本。
最後,市場缺乏 FHE 基礎設施的一個核心原因是我們缺少有效的方式來構建 FHE-RAM。一個可能的解決方向是針對一個沒有某些操作碼的 FHE-EVM 進行研究。
安全閾值解密(Secure Threshold Decryption)
挑戰:不安全 / 中心化的閾值解密
每個保密的共用狀態系統都基於加密和解密金鑰。由於不能信任任何單一方,因此解密金鑰在網路參與者之間透過多方計算(MPC)進行分片。
鏈上全同態加密(FHE)最具挑戰性的方面之一是構建一個安全且高性能的閾值解密協議。主要有兩個瓶頸:(1)基於 FHE 的計算引入了顯著的「開銷」,因此需要高性能的節點,這本質上減少了驗證者集合的潛在規模;(2)隨著參與解密協議的節點數量增加,延遲也會增加。
至少目前為止,FHE 協議依賴於驗證者中的大多數是誠實的(honesty majority),然而如上所述,鏈上 FHE 意味著較小的驗證者集合,因此存在更高的串謀和惡意行為的可能性。
如果閾值節點串謀作惡怎麼辦?它們將能夠繞過協議,基本上解密任何東西,包括用戶輸入到任何鏈上資料。此外,更要注意的是在當前系統中解密協定可以不被察覺地發生(即「無聲攻擊」)。
解決方案:改進的閾值解密或動態 MPC
有幾種可能的方法來解決閾值解密的缺點。(1)啟用 n/2 閾值,這將使串謀更加困難;(2)在硬體安全模組(HSM)內運行閾值解密協定;(3)使用基於受信任執行環境(TEE)的閾值解密網路,由去中心化鏈控制認證,允許動態金鑰管理。
與其利用閾值解密,更可能的情況是使用 MPC。一個在鏈上 FHE 中可以使用的 MPC 協議的現象級的例子:Odsy 的新的 2PC-MPC,這是第一個非串謀且大規模去中心化的 MPC 演算法。
另一種方法可能是僅使用用戶的公開金鑰來加密資料。然後驗證者處理同態操作,必要時用戶自己可以解密結果。雖然這只適用於特定的使用案例,但我們完全可以避免閾值假設。
總結來說,鏈上 FHE 需要一個高效的 MPC 實現,這種實現具備如下特點:(1)即使在存在惡意行為者的情況下也能工作;(2)引入最小的延遲;(3)允許無需許可 / 靈活的節點加入。
用戶輸入和計算方的零知識證明(ZKP)
挑戰:用戶輸入和計算的可驗證性:
在 Web2 世界中,當我們請求執行一個計算任務時,我們完全信任某個公司會按照他們承諾的方式在幕後運行這個任務。在 Web3 中,這個模型完全顛倒了。我們不再依賴公司的聲譽並簡單地相信他們會誠信做事,而是在一個無需信任的環境中運作,這意味著使用者不應該需要信任任何人。
雖然全同態加密(FHE)允許處理加密資料,但它無法驗證用戶輸入或計算的正確性。如果沒有驗證的能力,FHE 在區塊鏈的背景下幾乎沒有用處。
解決方案:用戶輸入和計算方的 ZKP:
雖然 FHE 允許任何人對加密資料進行任意計算,但 ZKP 允許人們在不透露底層資訊本身的情況下證明某事是真實的。那麼它們是如何相關的呢?
FHE 和 ZKP 結合在一起有三個關鍵方式:
- 使用者需要提交一個證明,表明他們的輸入密文是正確的格式。這意味著密文符合加密方案的要求,而不僅僅是任意的資料字串。
- 使用者需要提交一個證明,表明他們的輸入明文滿足給定應用程式的條件。例如,帳戶餘額大於轉帳金額。
- 驗證節點(即計算方)需要證明他們已正確執行 FHE 計算。這被稱為「可驗證的 FHE」,可以看作是 rollups 所需 ZKP 的類比。
為了進一步探索 ZKP 的應用:
1. 密文的 ZKP
FHE 建立在基於格(lattice-based)的密碼學上,這意味著加密原語的構造涉及格(lattice),這些格是後量子(post-quantum)安全的。相比之下,流行的 ZKP,如 SNARKs、STARKs 和 Bulletproofs,並不依賴於基於格的密碼學。
為了證明用戶的 FHE 密文格式正確,我們需要展示它滿足某個帶有環中元素(entries from rings)的矩陣 – 向量方程,並且這些元素的數值是小的。本質上,我們需要一個為處理基於格關係(lattice-based relations)而設計的、在鏈上驗證成本效率高的證明系統,這是一個開放的研究領域。
2. 明文輸入的 ZKP
除了證明格式正確的密文外,使用者還需要證明他們的輸入明文滿足應用程式的要求。幸運的是,與之前的步驟不同,我們可以利用通用的 SNARKs 來證明用戶輸入的有效性,從而使開發者能夠利用現有的 ZKP 方案、庫和基礎設施。
然而,挑戰在於我們需要「連接」這兩個證明系統。連接意味著我們需要確保使用者對兩個證明系統使用了相同的輸入。否則,惡意使用者可能會欺騙協議。這裡需要再次強調,這是一個極其困難的密碼學壯舉,也是一個早期研究的開放領域。
Sunscreen 已經為此奠定了基礎,他們的 ZKP 編譯器支援 Bulletproofs,因為它最容易與 SDLP 連接。針對「連接」FHE 和 ZKP 編譯器的研究也在不斷推進。
Mind Network 一直在引領 ZKP 的整合,以確保零信任輸入和輸出,同時利用 FHE 進行安全計算。
3. 正確計算的 ZKP
在現有硬體上運行的 FHE 極其低效和昂貴。正如我們之前所見的可擴展性三難問題的動態表現,那些對節點資源要求較高的網路無法擴展到足夠的去中心化水準。一個可能的解決方案是一個被稱為「可驗證的 FHE」的過程,其中計算方(驗證者)提交一個 ZKP 來證明交易的誠實執行。
一個可驗證的 FHE 的早期原型可以透過一個名為 SherLOCKED 的專案展示。本質上,FHE 計算被載入到 Risc ZERO 的 Bonsai zkVM 上,該 VM 在鏈下處理加密資料上的計算,並返回帶有 ZKP 的結果,並在鏈上更新狀態。
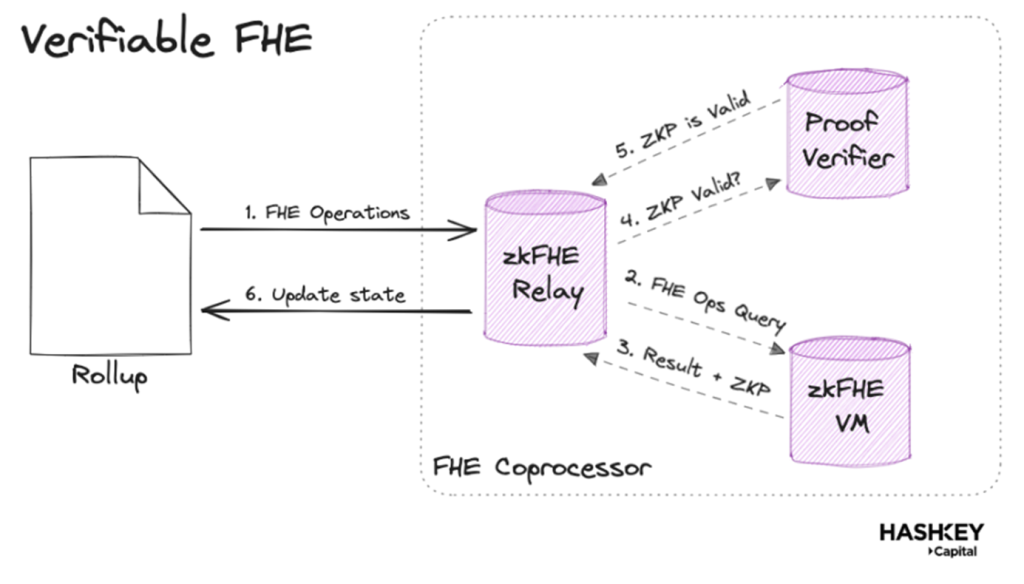
舉一個利用 FHE 輔助處理器的最近的例子:Aztec 的鏈上拍賣演示。正如我們之前所討論的,現有的 FHE 鏈使用閾值金鑰加密整個狀態,這意味著系統的強度僅取決於其閾值委員會(threshold committee)。相反,在 Aztec 中,使用者擁有自己的資料,因此不受閾值安全假設的約束。
最後,重要的是要瞭解開發者可以在哪裡首先構建 FHE 應用程式。開發者可以在 FHE 支援的 L1、FHE rollup 上構建他們的應用程式,或者在任何 EVM 鏈上構建並利用 FHE 輔助處理器。每種設計都有其自身的權衡,但我們更傾向於設計良好的 FHE rollups(由 Fhenix 開創)或 FHE 輔助處理器,因為它們從乙太坊中繼承了安全性等其他好處。
直到最近,在 FHE 加密資料上實現欺詐證明還是複雜的,但最近 Fhenix.io 的團隊展示了如何使用 Arbitrum Nitro 堆疊與 FHE 邏輯編譯到 WebAssembly 來實現欺詐證明。
FHE 的資料可用性(DA)層
挑戰:缺乏可定制性和輸送量
雖然在 Web2 中「存儲」已經商品化,但在 Web3 中情況並非如此。考慮到全同態加密(FHE)維持著超過 10000 倍的資料膨脹,我們需要確定在哪裡存儲大量的 FHE 密文。如果給定的 DA 層中的每個節點操作者都要下載並存儲每個 FHE 鏈的資料,那麼只有機構操作者才能跟上需求,從而增加了中心化的風險。
關於輸送量,Celestia 的最高速度為 6.7 MB/s,如果我們想運行任何形式的 FHEML,我們將需要每秒數 GB 的頻寬。根據 1k(x) 最近分享的資料,由於設計決策限制了輸送量(有意為之),現有的 DA 層無法支援 FHE。
解決方案:水準擴展 + 可定制性
我們需要一個能夠支援水準可擴展性的 DA 層。現有的 DA 架構將所有資料傳播到網路中的每個節點,這是可擴展性的一個主要限制。相反,隨著更多 DA 節點進入系統,水準可擴展性意味著每個節點存儲的資料量減少,隨著更多區塊空間的可用,性能和成本得到改善。
另外,考慮到與 FHE 相關的大量資料的大小,為開發者提供更高級別的糾刪碼閾值(erasure coding thresholds)定制化是有意義的。換句話說,開發者對 DA 系統的保證感到什麼程度的舒適?是基於權益的加權還是基於去中心化的加權。
EigenDA 的架構可以作為 FHE 的 DA 層某種可能性的一個基礎。它的水準擴展性、結構成本降低、DA 和共識的解耦等屬性,都為能夠支援 FHE 的可擴展性水準鋪平了道路。
最後,一個更高維度的想法可能是為存儲 FHE 密文構建優化的存儲槽,因為密文遵循特定的編碼方案,所以擁有優化的存儲槽可能有助於高效使用存儲空間和更快的檢索。
全同態加密(FHE)硬體
挑戰:低性能的全同態加密(FHE)硬體
在鏈上全同態加密(FHE)應用的推廣中,一個主要問題是由於計算開銷導致的顯著延遲,這使得在任何標準處理硬體上運行 FHE 變得不切實際。這種限制源自於與記憶體的大量交互,這是由於處理器需要處理巨大的資料量。除了記憶體交互外,複雜的多項式計算和耗時的密文維護操作也帶來了大量的開銷。
為了深入理解 FHE 加速器的狀態,我們需要揭開其中具體設計的面紗:針對特定應用的 FHE 加速器與可泛化的 FHE 加速器。
FHE 的計算複雜性和硬體設計的核心始終與給定應用所需的乘法數量有關,稱為「同態操作的深度」。在特定應用的情況下,深度是已知的,因此系統參數和相關計算是固定的。因此,針對特定應用的硬體設計將更容易,並且通常可以優化以獲得比可泛化加速器設計更好的性能。在一般情況下,如果需要 FHE 支援任意數量的乘法,需要引入 bootstrapping 技術來移除同態操作中積累的部分雜訊。 bootstrapping 技術代價比較高,需要大量硬體資源,包括晶片記憶體、記憶體頻寬和計算,這意味著硬體設計將與特定應用的設計大不相同。因此,儘管英特爾、Duality、SRI、DARPA 等產業重要參與者在 GPU 和 ASIC 設計方面的工作無疑在提高上限,但它們可能無法一對一地應用於支援區塊鏈場景。
在開發成本方面,可泛化硬體需要比特定應用的硬體更多的資本進行設計和製造,但其靈活性允許硬體在更廣泛的應用範圍內使用。另一方面,對於特定應用的設計,如果應用的需求變化並需要支援更深層次的同態計算,則需要將特定應用的硬體與一些軟體技術(如 MPC)結合使用,以實現與可泛化硬體相同的目的。
值得注意的是,與特定應用用例(例如 FHEML)相比,鏈上 FHE 的加速要困難得多,因為它需要能夠處理更一般的計算,而不是更具特定性的集合。例如,fhEVM 開發網路目前的交易處理速度僅限於個位數 TPS。
鑒於我們需要針對區塊鏈定制的 FHE 加速器,另一個考慮因素是:從 ZKP 硬體到 FHE 硬體的可轉移性到底如何?
ZKP 和 FHE 之間存在一些共同的模組,例如數論變換(NTT)和底層的多項式操作。然而,這兩種情況中使用的 NTT 的位寬(bit width)不同。在 ZKP 中,硬體需要支援 NTT 的多種位元寬,例如 64 位和 256 位,而在 FHE 中,由於使用了剩餘數系統,NTT 的運算元較短。其次,ZKP 中處理的 NTT degree 通常高於 FHE。由於這兩個原因,設計一個同時對 ZKP 和 FHE 都有令開發者滿意的性能的 NTT 模組並非易事。除了 NTT 之外,FHE 中還存在一些其他的計算瓶頸,如自同構(automorphism),這些在 ZKPs 中並不存在。將 ZKP 硬體簡單轉移到 FHE 設置的一種方法是將 NTT 計算任務載入到 ZKP 硬體上,並使用 CPU 或其他硬體處理 FHE 中的其餘計算。
總結這些挑戰,使用 FHE 在加密資料上進行計算曾經比在明文資料上慢 100,000 倍。然而,由於較新的加密方案和 FHE 硬體的最新發展,目前的性能已經顯著提高到比明文資料慢大約 100 倍。
解決方案:
1. FHE 硬體的改進
許多團隊正在積極構建 FHE 加速器,但他們並未專注於特定於可泛化區塊鏈計算(例如 TFHE)的 FHE 加速器。一個針對區塊鏈的特定硬體加速器示例是 FPT,一種固定點 FPGA 加速器。FPT 是第一個重度利用 FHE 計算中固有雜訊的硬體加速器,它完全使用近似的固定點算術實現 TFHE 引導。另一個對 FHE 可能有用的項目是 BASALISC,這是一個旨在雲端大幅加速 FHE 計算的硬體加速器架構的系列。
正如前面提到的,FHE 硬體設計中的一個主要瓶頸是與記憶體的大量交互。為了繞過這個障礙,一個潛在的解決方案是盡可能減少與記憶體的交互。處理器記憶體(PIM)或近記憶體計算(near memory computation)可能在這種情況下有所説明。PIM 是應對未來電腦系統的「記憶體牆(memory wall)」挑戰的有希望的解決方案,它允許記憶體同時承擔計算和存儲功能,承諾對計算與記憶體關係進行根本性改革。在過去十年中,設計解決此問題的非易失性記憶體方面取得了巨大進展,例如電阻式 RAM、自旋轉移扭矩磁性 RAM 和相變記憶體。使用這種特殊記憶體,已有研究顯示在機器學習和基於格的公開金鑰加密中顯著改善了計算性能。
2. 優化的軟體和硬體
在最近的發展中,軟體被公認為硬體加速過程中的一個關鍵組成部分。例如著名的 FHE 加速器,如 F1 和 CraterLake,使用編譯器進行混合軟硬體共同設計。
隨著這一領域的發展,我們可以期待與針對區塊鏈的 FHE 編譯器共同設計的功能齊全的編譯器。FHE 編譯器可以根據相應 FHE 方案的成本模型優化 FHE 程式。這些 FHE 編譯器可以與 FHE 加速器編譯器整合,透過結合硬體級別的成本模型,改善端到端性能。
3. 網路 FHE 加速器:從垂直擴展到水準擴展
現有的針對 FHE 硬體加速的努力主要集中在「垂直擴展」,即專注於單個加速器的垂直改進。另一方面,「水準擴展」則關注於透過網路橫向連接多個 FHE 加速器,這可能會大大提高性能,類似於與零知識證明(ZKPs)的並行證明生成。
FHE 加速的一個主要困難是資料膨脹問題:指的是在加密和計算過程中發生的資料大小顯著增加,為晶片內和晶片外記憶體之間的高效資料傳輸帶來挑戰。
資料膨脹對透過網路橫向連接多個 FHE 加速器構成了顯著的挑戰。因此,FHE 硬體與網路的共同設計將是未來研究的一個有前景的方向。例如針對 FHE 加速器的自我調整網路路由:實現一種基於即時計算負載和網路流量,來動態調整 FHE 加速器之間資料路徑的路由機制。這將確保最佳的資料傳輸速率和高效的資源利用。
結束語
FHE 將從根本上重新構建我們在各個平台上保護資料的方式,為一個前所未有的隱私新時代鋪平道路。構建這樣一個系統將需要在 FHE、零知識證明(ZKPs)和多方計算(MPC)上取得重大進展。
當我們進入這個新領域時,密碼學家、軟體工程師和硬體專家之間的協作努力將是必不可少的。更不用說立法者、監管機構等,因為合規性是實現主流採用的唯一途徑。
歸根結底,FHE 將站在數字主權變革浪潮的前沿,預示著一個資料隱私和安全不再是相互排斥而是密不可分的未來。
特別鳴謝
非常感謝 Mason Song(Mind Network)、Guy Itzhaki(Fhenix)、Leo Fan(Cysic)、Kurt Pan、Xiang Xie(PADO)、Nitanshu Lokhande(BananaHQ)的審閱。我們期待讀者能去瞭解這些人在該領域所做的令人印象深刻的工作和努力!
【免責聲明】市場有風險,投資需謹慎。本文不構成投資建議,用戶應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
*原文內容及圖片來源: https://foresightnews.pro/article/detail/48995









