


2017年6月,Google發表了一篇名為Attention Is All You Need(注意力是你需要的全部)的論文。
這篇論文由8名發量茂密的AI科學家聯合撰寫,他們在論文裡創造性地提出了一種“注意力機制”,並基於此開發一個名叫Transformer(變形金剛)的深度學習模型——一位作者認為叫“注意力模型”過於無聊,就用玩梗的心態起了這個名字。

8名作者大都離開Google,選擇創業
從Transformer模型被提出的那一刻起,人工智能的歷史進程被驟然加速了。研究者發現Transformer在自然語言處理(NLP)領域的效率奇高,相比傳統RNN(循環神經網絡)優勢明顯,於是很快便成為NLP研究者們推崇的首選模型。
Google的重大進展,卻讓OpenAI的工程師們徹夜難眠。OpenAI當年成立的初衷,就是打破Google在人工智能領域的壟斷,而面對這只橫空出世的“變形金剛”,他們做了一個重大決定:乾脆就用Transformer這件敵人的武器,來跟Google正面硬剛。
2018年6月,在“變形金剛”誕生一周年之際,OpenAI推出了基於Transformer模型的GPT-1,其中GPT裡面的“T”,就是Transformer的首字母。此後,OpenAI沿著這條路線把GPT-1持續迭代到本周剛發布的GPT-4,並讓ChatGPT火遍了全球。
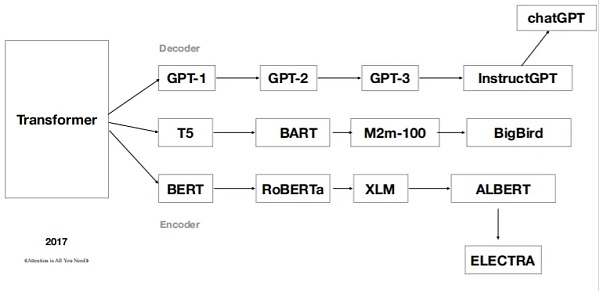
Transformer家族譜系,量子學派[7]
標杆旗幟一出,全球科技巨頭就蜂擁而至,紛紛推出了自家基於Transformer的大模型,如Google的BERT,微軟的Turing-NLG,英偉達的Megatron、國內華為的鵬程盤古、阿里的M6、百度的文心一言等大模型都是基於Transformer來構建。
更進一步,研究者發現Transformer不僅能夠處理語言,處理圖像能力也很猛,遠勝於傳統CNN(卷積神經網絡)模型。2020年,Google科學家提出了Vision Transformer ( ViT )概念[1],給計算機視覺領域的人工智能也裝上了火箭助推器。
到本文開始撰寫時,Attention Is All You Need這篇論文已經被引用了68,147次,成為人工智能歷史上被引數量第三高的論文。應該說,Transformer的出現扣動了此輪人工智能熱潮的板機,你在朋友圈刷到的所有AI熱點,幾乎都跟這個“變形金剛”有關。
站在Transformer模型上,OpenAI成為全球最耀眼的明星,而發明人Google也讓世界在AlphaGo之後再次敬畏起了它的實力,兩家公司一度打起了大模型的軍備競賽,而全球其他科技巨頭也不想只做圍觀者,要么已經躬身入局,要么正在摩拳擦掌。
其實,受Transformer啟發,把它運用到爐火純青並點燃另一場AI革命的公司還有一家,就是特斯拉。
01借船:馬斯克的“人工智能恐懼症”
在梳理特斯拉的AI軌蹟之前,讓我們先來了解一下伊隆·馬斯克的“人工智能恐懼症”。
這個星球上唯一能讓馬斯克做噩夢的,不是貝索斯的光頭,也不是薛定諤的剎車片,而是人工智能。2014年他就在推特上寫道:“我們要對人工智能格外小心,它可能比核武器更危險。”在之後的一次訪談中,他又危言聳聽道:“當人工智能成為不死的獨裁者時,世界將永遠無法掙脫(它的控制)。”
可能是覺得原子彈的類比還不夠震撼,馬斯克在2017年把人工智能的威脅進一步比做北朝鮮[2]——他在twitter表示人工智能“Vastly more risk than North Korea”。隨後又強烈宣稱“人類應該像監管食品、藥物、飛機和汽車一樣來監管人工智能。”
為何如此害怕?馬斯克2018年在“西南偏南”大會上對話《西部世界》編劇喬納森·諾蘭時解釋道[3]:我通常不提倡監管,而且傾向於減少這種枷鎖,但是“人工智能把我嚇壞了,它的能力比幾乎任何人知道的都要強,而且進化速度是指數級的。”

在《西部世界》裡,馬斯克的前妻Riley扮演一個高級AI
不過,馬斯克一方面維持著“最恐人工智能的碳基生物”這一人設,一方面卻在大干快上地投資AI。
2013年,馬斯克個人投資了DeepMind;2015年他參與了OpenAI的眾籌發起和Vicarious的B輪融資;2016年,馬斯克又創辦了腦機接口公司NeuraLink;而特斯拉也通過收購把DeepScale、GrokStyle、Perceptive Automata等人工智能公司納入囊中。
特斯拉更是很早就開始佈局人工智能。2013年特斯拉憑藉Model S的熱售市值突破100億美元,馬上開始籌劃進軍自動駕駛。在5月份馬斯克跟Google創始人的一次對談中這樣講:“飛機的自動駕駛儀(Autopilot)是一件很棒的東西,汽車也應該擁有它。”
在當時,“自動駕駛”對傳統汽車廠商來說更像是一個科幻概念。1970年代全球汽車巨頭們定義了DAS(駕駛員輔助系統),然後沿著這條路線謹慎推進,“自動駕駛”一方面大廠們不想幹(會帶來無窮的法律噩夢),另一方面也的確是乾不了。
2014年,國際汽車工程師學會(SAE)把廣義上的“自動駕駛”分成了6類。可以看到,傳統車企在過去幾十年基本上都在L0~L1級之間原地踏步,如果要達到L2級甚至更高,汽車就必須藉助人工智能,而想要做到這一點,就要把汽車變得更像一台計算機,而非一個單純的機械電子部件組合體。
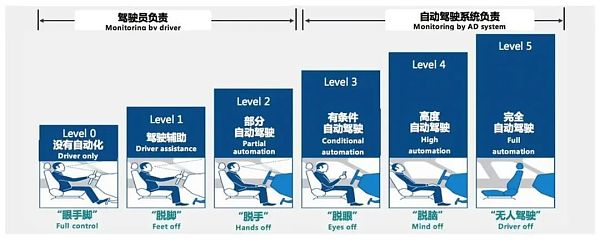
自動駕駛6個級別,未來智庫[4]
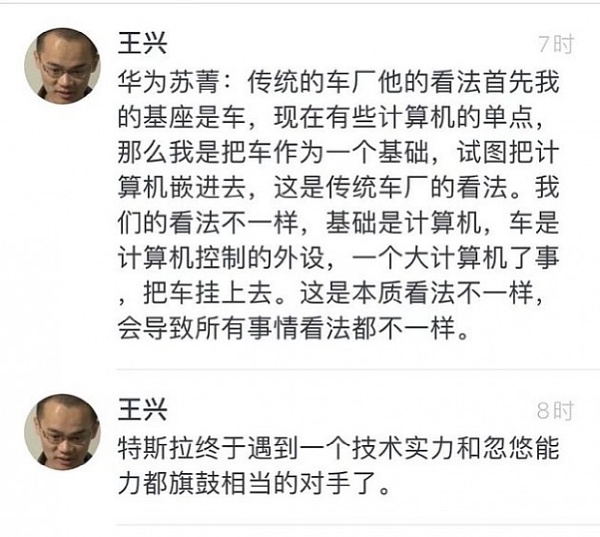
而特斯拉在Model S上,就已經實現的電子電氣架構革新,讓汽車更像一台“四個輪子的計算機”。這種理念後來被前華為蘇菁用大白話總結了出來:傳統車廠認為車的基座是車,然後把計算機嵌進去;我們則認為汽車的基座是計算機,然後把車掛上去。
Modle S改電子電氣架構初衷是為了降成本,比如減少又貴又沉的汽車線束,但新架構至少能讓汽車的各部分聽從“大腦”的統一指揮(具體怎麼做的詳見我們之前的文章[12][13]),等於為人工智能的落地搭了一套毛胚房(但還算不上精裝修)。
毛胚房準備了,但要讓AI真正“拎包入住”——實現L2級以上的“自動駕駛”,還需要什麼東西?
我們通常認識的“自動駕駛”,就是汽車利用各種傳感器,收集周圍環境數據,然後汽車的大腦(核心是芯片)根據算法來解析這些數據,進而控制車輛行為。比如攝像頭看到前方突然竄出一條狗,大腦解析後發出緊急剎車的指令,讓汽車停下來。
在這個過程中,識別出前方竄出來的到底是一條德國牧羊犬,還是一隻黑色垃圾袋,就需要一套“算法”了。這些算法,需要提前載入到汽車的“大腦”裡,輸入汽車各類傳感器採集到的數據,然後作出實時的判斷,進而控制汽車的行為。
汽車要在行駛過程中採集數據、加載算法、迅速作出判斷,本身的計算性能也不能掉鍊子,尤其是高速行進時,決策晚1ms都可能會釀成大禍,如果“卡機”更是災難。因此,汽車上搭載的芯片性能也不能糊弄,要有足夠的算力。
而那些事先載入汽車大腦的算法從何而來?在早期,碳基程序員們用if-else語句來撰寫算法,但在機器學習問世之後,科技公司們開始構建計算平台,匯聚了從終端提取和模擬生成的海量數據,在更高算力的芯片驅動下,不斷訓練,形成算法。
圖片來源:aionlinecourse
到這裡,自動駕駛“四要素”就很明確了:1. 感知數據2. 核心算法3. 終端芯片4. 計算平台。
但2013年的特斯拉還是一個名副其實的“小廠”,在四座大山面前基本上毫無積累,尤其是芯片和算法需要投入大量研發經費。馬斯克此時的策略也很務實:造不如買。當時能進入特斯拉視野的供應商有且只有一家——以色列公司Mobileye。
Mobileye的名字包含“移動”和“眼睛”兩個詞,這家公司由號稱“中東哈佛”的以色列希伯來大學教授Amnon Shashua於創建。自1999年成立之後,專注於開發自動/輔助駕駛技術,2014年在紐交所上市,2017年被英特爾以153億美金的天價併購。
在上文提到的自動駕駛“四要素”中,Mobileye最擅長什麼?核心算法。
跟近些年“算力論英雄”的情形不同,初期的自動/輔助駕駛對算力的要求並不高。與如今L4級自動駕駛動輒400 TOPS、L5級更是達到4000 TOPS的算力要求不同,L1級的自動駕駛所需算力甚至不到1 TOPS,L2級也僅僅是在2 TOPS附近徘徊。
L1級自動駕駛跟“自動駕駛”相隔十萬八千里,基本上就是“駕駛員輔助”,比如自適應巡航、自動剎車、車道保持等功能,實現起來的確不用很強的計算能力,只需要廉價的攝像頭雷達配合先進的圖像識別算法,而這也正是Mobileye的強項。
在創立的前10年,Mobileye僅僅靠純軟件方案的視覺算法就實現了盈虧平衡。一直到2008年,Mobileye才推出了第一代自動駕駛芯片EyeQ1,由台積電代工,採用ARM內核和180nm工藝,而同期初代iPhone搭載的三星S5L8900芯片已經用上了90nm工藝。
到了2014年,Eye系列已經迭代至Q3,截至2013年年底,產品累計銷量突破100萬台。雖然Q3算力仍然是可憐的0.25 TOPS,但其捆綁銷售的算法夠香,對於急於上車智能駕駛、又苦於沒有軟件和算法開發能力的廠商來說,屬於瞌睡遇到枕頭。

Mobileye EyeQ3芯片
馬斯克不喜歡Mobileye,尤其是後者將算法直接封裝進芯片裡,交付客戶的是一個“黑盒”,裡面的算法無法更改。但不喜歡也沒辦法,Mobileye市場份額接近壟斷,你愛買不買,寶馬奔馳福特都得低頭,特斯拉也只好乖乖地接受這種“店大欺客”。
2014年10月,特斯拉發布了第一個自動駕駛方案——Autopilot1.0版本,其中的硬件模塊稱之為Hardware 1.0(簡稱HW1.0)。這個方案把Mobileye EyeQ3作為硬件模塊的大腦,另外還配備一個前置攝像頭、12個超聲波雷達和1個毫米波雷達。
自此,2014年10月之後生產的新車都會默認搭載HW1.0硬件,但用戶此時還不能直接用——特斯拉採用的是“硬件先行,軟件更新”的方式,先裝硬件,再OTA升級,因此一直到2015年10月特斯拉v7.0版更新後,Autopilot1.0才正式被“點亮”。
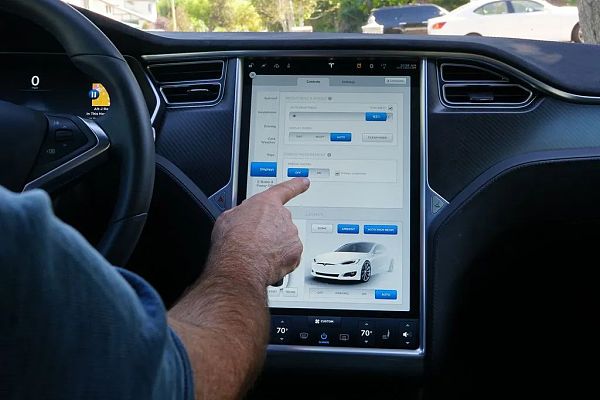
早期的Autopilot1.0界面
在Mobileye“上車”的那一刻,馬斯克就暗中準備自研自動駕駛的算法、芯片和計算平台。
2015年馬斯克試圖拉攏矽谷著名黑客George Hotz來特斯拉搞無人駕駛,承諾如果成功替代Mobileye,特斯拉會一次性給他“數百萬美元獎金”,但被對方拒絕,隨後Bloomberg的一篇報導將兩人的郵件披露出來[5],立馬引來了Mobileye的質問。
被Mobileye“卡脖子”的特斯拉只好在官方網站上發了一份聲明,表示Mobileye提供的芯片和算法仍然是“全世界最好”,特斯拉還會繼續使用。然後馬斯克親自在twitter上轉發了這份聲明,才打消了Mobileye的怒火,避免了特斯拉被“斷供”。
事件平息後,馬斯克加速推進“自主可控”計劃。2016年1月,傳奇的AMD首席架構師Jim Keller被挖到了特斯拉,他的長期戰友Peter Bannon也在1個月之後來到馬斯克的陣營——特斯拉跟Mobileye“脫鉤”已經只是一個時間問題。
分手的決心如此強烈,馬斯克就差一個冠冕堂皇的理由和一個暫時替代Mobileye的備胎。很快,它們都來了。
02 過渡:一段跟黃仁勳的塑料友誼
2016年5月,一輛開啟自動駕駛模式的Model S在佛羅里達州撞車,40歲的司機Joshua Brown當場死亡。
這輛Model S撞上的是一輛貨車的白色車廂。當後者橫穿馬路時,特斯拉的Autopilot系統雖然通過毫米波雷達檢測到了車廂,但誤把藍天映襯下的白色車廂當成一塊路牌,AEB(自動緊急制動系統)於是沒有做任何的反應,車就徑直撞上去了。

慘烈的Model S車禍現場
這是人類歷史上已知的第一起自動駕駛事故,自然引起全球輿論關注,美國國家運輸安全委員會(NTSB)發布了足足500頁的報告。調查人員發現司機Joshua Brown在駕駛過程中也不老實,90%的時間雙手離開方向盤,並忽視了七次系統警告。
司機雖有錯,但企業也得背鍋。特斯拉發現如果要跟橫穿馬路的車輛相撞,Mobileye的EyeQ3芯片無法提供足夠的算力,要等到兩年後發布的EyeQ4才行,而Mobileye在事故的聲明里又暗搓搓地甩鍋特斯拉,這讓馬斯克更加堅定了踢開Mobileye的決心。
5個月後,特斯拉發布了Autopilot 2.0和硬件模塊HW 2.0,徹底跟Mobileye分道揚鑣。接替它的是黃仁勳的英偉達。
這裡插一下:特斯拉自動駕駛方案的名字眼花繚亂,最開始就叫做Autopilot,後來引入一個高級選配方案FSD(Full Self-Driving),兩者就是同一套系統的兩檔產品,用戶多花錢,就可以激活更多功能,背後的硬件叫做Hardware(1.0→4.0)。
英偉達在自動駕駛方面其實也是一枚新兵蛋子。在2015年1月,黃仁勳向世界發布第一代了NVIDIA Drive平台,這個平台由兩部分組成:數字座艙(CX)和自動駕駛(PX),兩者都使用英偉達Tegra X1——任天堂switch的同款芯片。
Tegra是英偉達移動芯片家族的名字,當年坑了不少廠商,比如HTC和小米,一直被高通摁著摩擦。後來老黃乾脆放飛自我,把在顯卡領域練就的“砌算力”大法發揮到極致,功耗發熱猛增,基本退出手機市場,但在自動駕駛領域卻重獲新生。
以Tegra X1為例,其採用標準的CPU+GPU架構,CPU部分採用4顆Arm A57內核和4顆A53 內核,核心數總計8顆;而GPU部分則採用Maxwell架構,核心數高達256顆。這種“暴力堆砌”下,單顆Tegra X1的算力居然攀到了1 TFlops。
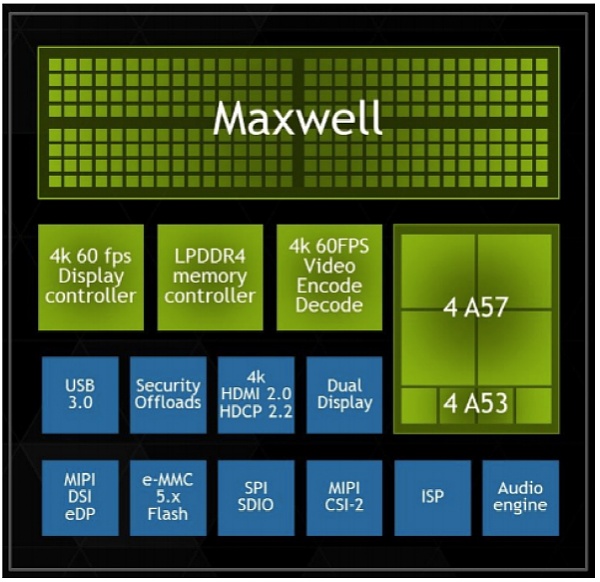
Tegra X1 圖片來源:英偉達
1 TFlops是什麼概念呢?TFlops指的是“每秒萬億次浮點運算能力”,1996年英特爾幫美國能源部Sandia國家實驗室製造了一台名叫“ASCI Red”的超級計算機,佔地1600平方英尺耗電500千瓦,用來模擬核彈頭,它的算力就是1.06 TFlops。
英偉達的“算力大法”,正好是自動駕駛由L1向L2、L3演進時急需的東西。
比如L1級的“單車道定速巡航”功能下,車載芯片只需要處理有限的數據量,但一旦進化到L2級別的“自動變道”,車輛不僅要識別車道和周圍車輛,還要實時算出最優變道決策,算力需求提升了一個數量級。相比單純地用CPU來提供算力,英偉達“CPU+GPU”模式能更好地匹配自動駕駛的需求。
為什麼?簡單說,CPU(中央處理器)和GPU(圖形處理器)均由控制單元(Control)、運算單元(ALU)、存儲單元(DRAM)、緩存(Cache)等幾個部分構成,兩者區別主要在於各個單元的數量配比,尤其是運算單元的數量配比。
運算單元是芯片數據計算的中心,由算術邏輯部件(ALU)組成,ALU即大家口中的“核”,所謂8核CPU指的便是有8個計算單元。為圖像處理和矩陣計算而生的GPU,與CPU的最大差別在於可以暴力疊加成千上萬個ALU進行並行運算。
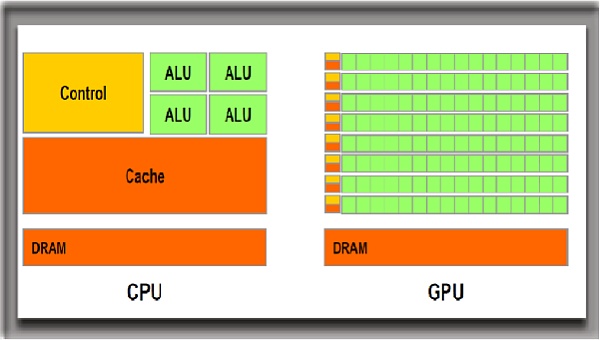
簡單類比,CPU像一位數學系教授,能力全面,GPU則像他手下的一年級本科生,偏科嚴重,只會算數。教授平時擅長統籌全局,發號施令,他自己雖然也會算數,甚至抵得上兩三個本科生,但顯然比不過100個本科生疊加在一起的“算力”。
當GPU遇到人工智能後,開始大放異彩。2006年,英偉達推出基於GPU的CUDA開發平台,開發者可以通過這一平台,使用C語言編寫程序以解決複雜的計算問題,換言之,原本只用做3D渲染的GPU變得更加通用,可執行的任務更加多樣。
2009年,斯坦福大學的Raina、Madhavan及吳恩達在一篇論文中論述了GPU在深度學習方面相對CPU的大幅優勢[6],將AI訓練時間從幾週縮短至幾小時。這篇論文為人工智能的硬件實現指明了方向。GPU大大加速了AI從論文走向現實的過程。
因此,特斯拉從Mobileye切換到英偉達不僅是換供應商這麼簡單,而是把人工智能硬件實現的利器——GPU裝上了車,等於把“毛胚房”換成了“精裝房”,實現了AI算法的拎包入住,同時也把“電動車”和“人工智能”兩大時代主題連接在了一起。
特斯拉在2016年10月發布的HW 2.0硬件平台,包含8個攝像頭、1個毫米波雷達、12個超聲波雷達,以及英偉達DRIVE PX2定制主板,主板上面搭載了Tegra X2 CPU和升級為Pascal架構的GPU,算力是10 TOPS,大概是Mobileye EyeQ3的整整40倍。
“新女友”看起來貌美如花,但特斯拉為了這次分手其實付出了不小的代價。
HW 2.0的硬件性能雖然優越,但軟件上卻是短板,特斯拉內部團隊和英偉達在算法上都還達不到Mobileye的水準。比如一直道HW 2.0發布的3個月後,特斯拉才把自適應巡航控制、前方碰撞預警和方向盤自動轉向等基本功能給匆忙地做出來。
因此,雖然特斯拉自2016年10月後出廠的車都標配了HW 2.0,但一直到2017年上半年才把Autopilot 1.0的功能都實現出來。因此有用戶調侃道:“搭載了更強勁硬件的新車車主們等了足足半年,總算可以享受跟老車主一樣的輔助駕駛功能了。”
但頂著客戶流失的風險,特斯拉也要把Mobileye換成英偉達。除了感情因素之外,更重要的是NVIDIA Drive是一個開放平台,自由度很高,特斯拉可以一邊在英偉達的平台上練手,一邊積累自己的軟件和算法能力,為最後的自研鋪平道路。
對“渣男”來說,所有的「現任」都將是「前任」。在擁抱英偉達的同時,特斯拉的自研究也在緊鑼密鼓地進行著。
03自研:吃著碗裡的,看著鍋裡的
當馬斯克開始搞AI時一定會有感觸:相比於製造業,美國的AI和芯片人才實在是太多了。
跟從1980年代開始就逐步外遷的製造業不同,美國在計算機科學的三大應用領域——互聯網、軟件、芯片設計上一直保有雄厚的人才儲備。以ACM圖靈獎獲得者為代表的頂尖科學家在高校、產業和研究機構裡突破前沿,而數不清的高級工程師則在Google、蘋果、微軟、Intel等Top公司之間頻繁流轉。
特斯拉2015年籌備自研無人駕駛時,已是科技圈的當紅炸子雞,馬斯克有資本從矽谷大廠裡撬走各路牛人和大神。從2015年至今,特斯拉無人駕駛團隊的架構歷經多次調整,人員也熙來攘往,但無論是硬件還是軟件,馬斯克挑選的各個團隊負責人,基本上都是世界最頂級的科學家或工程師。
我們可以從幾個大牛的簡歷中窺探到特斯拉Autopilot團隊極高的人才密度:AMD K7/K8/Zen架構的開拓者Jim Keller、蘋果芯片團隊的核心成員Pete Bannon、Swift編程語言的發明人Chris Lattner、OpenAI首席科學家Andrej Karpathy……

特斯拉團隊(左起):硬件總監及Dojo負責人Ganesh Venkataramanan;工程總監Milan Kovac;人工智能總監Andrej Karpathy;軟件總監Ashok Elluswamy;總忽悠師Elon Musk ,2021 Tesla AI Day
這裡重點提一下Andrej Karpathy。這位出生於1986年的小哥是斯洛伐克人,15歲隨父母移民加拿大,2015年獲得斯坦福大學博士,導師是計算機大神李飛飛,在讀博期間他已經是人工智能屆的超級明星,畢業後直接參與創辦了OpenAI。
2017年,他被馬斯克厚著臉皮挖到了特斯拉,而從2017年到2022年,Andrej Karpathy一直擔任特斯拉人工智能總監,並直接向馬斯克匯報,直到2022年離職重返OpenAI。客觀地說,他是特斯拉人工智能團隊的最重要的締造者之一。

發量相對濃密時期的Andrej Karpathy
而在頂峰時,特斯拉Autopilot團隊擁有300多名頂級工程師(不包括1000多名數據標註員),其中200人專攻軟件,100人專攻硬件和芯片,馬斯克在一次採訪中說[8]:這些精英“人家隨便去哪兒都能找到工作,沒有誰是他們真正的老闆。 ”
在矽谷人才和自身光環的加持下,特斯拉不准備去抄英偉達和Mobileye的作業,那他們想怎麼幹?
自動駕駛的具體實現非常複雜,而且作為一門嶄新的科學,新技術、新路線、新突破層出不窮,但沿著我們前文提到自動駕駛的“四要素”(1. 感知數據2. 核心算法3. 終端芯片4. 計算平台)來出發,基本上就能理清馬斯克規劃的龐大藍圖。
首先,在「感知數據」方面,特斯拉選擇了“純視覺感知”方案,放棄了逐漸成熟的激光雷達、毫米波雷達等非視覺傳感器。這一做法在業內獨樹一幟,難度相比其他主流方案直接拉高了一個數量級,在業界也引起熱烈的討論甚至爭議。
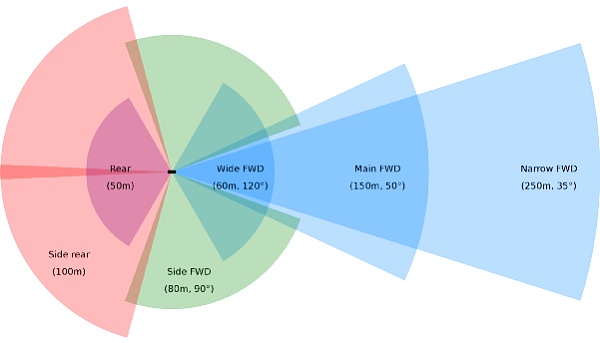
特斯拉8個攝像頭覆蓋範圍
自動駕駛領域大多數專家都認為“純視覺”方案不可取,不少用戶也頗有微詞,認為在技術不成熟的情況下就放棄雷達是對用戶安全的不負責任。馬斯克對這些批評置若罔聞,並公開嘲諷業界對高精度地圖和激光雷達等方案的依賴。
其次,在「核心算法」方面,簡單來說就是特斯拉通過8個攝像頭採集的2D圖像,使用複雜的感知神經網絡架構進行加工,構建出一個能夠表徵真實世界的3D向量空間,這個空間裡擁有自動駕駛決策場景裡所需要的幾乎所有信息,比如車道、行人、建築物等。
 從8個攝像頭到3D向量空間,2021 Tesla AI Day
從8個攝像頭到3D向量空間,2021 Tesla AI Day
基於這個3D向量空間,特斯拉設計了一個HydraNet架構——Hydra是希臘神話中“九頭蛇”的名字,意思是這套架構共享一個數據“軀幹”(BackBone),為1000多個任務的“頭”(Head)提供支持,比如物體檢測、交通燈識別、車道線預測等。
這些任務的算法大都由雲端的計算平台在吞噬了巨大數據量後訓練而來。因此,特斯拉的自動駕駛其實不存在“核心算法”的概念,搭載在汽車終端上的是一個複雜的基於神經網絡的系統,由無數個模塊組合而成,宛如一座巨大的迷宮。
第三,在「終端芯片」方面,由於需要實時構建龐大的3D向量空間,每一輛開啟FSD的特斯拉汽車都需要極強的算力來消化海量數據。馬斯克的應對思路非常清晰:招募團隊,自己從頭開始研發自動駕駛的終端芯片,替代掉英偉達的方案。
這裡需要區分的是:我們通常說的車載核心芯片通常有兩類,一類是給智能座艙提供算力的芯片,這一類特斯拉基本都外購成熟的消費級CPU,歷代車型用過英偉達Tegra3(2012-2018)、Intel A3950(2018-2021)和AMD 的Ryzen(2021-至今)。
另一類則是給自動駕駛提供算力的芯片,算力要求更高,Mobileye和英偉達Drive PX2提供的是這類,特斯拉要自研的也是這類。思路大致是:在“CPU+GPU”的基礎架構上再增添專門的AISC(專用集成電路),來解決潛在的算力瓶頸。
最後,在「計算平台」方面,特斯拉之前是購買英偉達的闆卡來搭建數據中心,但既然決定要自研車載終端芯片,乾脆把訓練算法的計算平台也一併自研。2019年4月,馬斯克在特斯拉Autonomy Day上首次公佈了超級計算機Dojo的研發計劃。
綜合來看,馬斯克試圖吃透無人駕駛的每一個環節,這是一個充滿野心和瘋狂的計劃。
特斯拉跟英偉達“分手”實屬必然。一方面馬斯克篤信“純視覺”方案,試圖跟其他廠商拉開差距,英偉達的通用硬件方案就無法滿足需求了;另一方面,Drive PX2的售價高達10000美元+,這對成本敏感體質的馬斯克來說是一個難以安眠的數字。
英偉達對特斯拉其實相當有誠意,除了在定價方面給予了很大折扣之外,黃仁勳還在社交媒體上曬出自己的特斯拉座駕以及和馬斯克的合照,讓人彷彿夢迴2005年蘋果與Intel的世紀牽手。但特斯拉基本上也在重複蘋果拋棄Intel的故事。

黃仁勳在社交媒體上分享自己的Model X
黃仁勳可能低估了特斯拉的決心和實力,在2018年8月的一次業績電話會議中,一位分析師問及特斯拉自研芯片的影響時,黃仁勳先是談了一下自研芯片的難度,然後說:“如果他們沒搞出結果,給我打電話,我會很樂意幫忙的。”
電話會議結束後,馬斯克立即在twitter上回應,措辭的塑料友誼感十足:“Nvidia製造了很棒的硬件,高度尊重黃總的公司。”同時又很司馬昭地表示:“我們的硬件需求是很獨特的,需要跟我們的軟件緊密匹配。”
2018年是特斯拉Autopilot自研的衝刺節點:人工智能總監Andrej Karpathy領導團隊通過大型神經網絡來訓練算法;硬件大神Jim Keller和接班人Pete Bannon主持終端FSD芯片的研發;元老級高管David Lau則帶領近百人的團隊改善數據採集和車機交互……
特斯拉能不能交出一張滿意答卷?不僅英偉達想知道,全世界想抄作業的人也都在等待著。
04答案:特斯拉是汽車公司,還是AI公司?
2021年8月19日,當Andrej Karpathy在特斯拉AI Day上展示Transformer時,全世界的友商都瞪大了眼睛。
如前文所述,特斯拉“純視覺”方案的第一步,就是把8個攝像頭採集的圖像提取特徵,融合成一個統一的三維向量空間。這個idea很符合“第一性原理”,是基礎中的基礎,但實現起來極難,傳統的基於2D圖像的CNN卷積根本解決不了問題。

極其複雜的3D向量空間
特斯拉的做法是用上了新鮮出爐的Transformer。在開頭我們講過,Transformer不僅處理自然語言在行,處理計算機視覺同樣是神器,在Google和OpenAI都工作過的Andrej Karpathy自然不會放過,在第一時間就帶領團隊將其用在3D向量空間的創建上了。
這是一個巨大的突破。客觀說只有解決了這個問題,特斯拉才有拋棄激光雷達的底氣。
具體實現的方法,感興趣的讀者可以詳讀參考文獻[15]。特斯拉率先使用Transformer之後,全球同行們紛紛跟隨。應該說,Transformer除了把GPT大模型送到全球聚光燈之下外,它還在每一台具備自動/輔助駕駛功能的汽車裡默默發揮著作用。
當然,Transformer模型也只是特斯拉自動駕駛算法系統的一個“零部件”,跟它一起發揮作用的還有無數新老技術。而且要注意:人工智能是一門日行千里、甚至在不斷加速的科學,今天的“神器”到了明天,可能就會被更好的算法和模型替代掉。
Karpathy的展示只是特斯拉“全棧自研”的一小部分,由於不同團隊進度的差異,面紗是逐步被揭開的。
首先亮相的其實是硬件。2019年4月,特斯拉終於發布了“自主可控”的自動駕駛硬件平台HW 3.0。全球科技圈對此期盼已久:老車主們重點關注能否免費升級,友商們紛紛掏出放大鏡準備認真“學習”,而對沖基金和類似System Plus這樣的諮詢公司則迅速行動,在第一時間對HW 3.0進行了拆解。

HW3.0和HW2.5(HW2.0的簡單升級)闆卡對比圖
HW3.0一共包含4746個零件,其中兩顆刻有Tesla標記的銀色FSD芯片最引人矚目。這款芯片是特斯拉硬件自研的最大成果,由三星在得克薩斯州奧斯汀的工廠代工,採用14nm FinFET工藝,面積大約為260平方毫米,集成了60億晶體管。
隨後,在2019年8月的IEEE的Hot Chips會議(高性能處理器頂會)上,特斯拉芯片負責人Pete Bannon(Jim Keller已離職)展示了FSD的內部結構,可以看到特斯拉沒有採用英偉達通常的CPU+GPU架構,而是採用高度定制的CPU+GPU+ASIC架構。

特斯拉第一代FSD芯片架構
這裡的ASIC指的便是佔據整塊芯片最大面積的兩顆神經網絡處理單元(NNA),即NPU。每顆NPU核的峰值性能可以達到每秒36.86萬億次運算(TOPS),功耗卻只有7.5W。與之相比,GPU內核只提供0.6TOPS的算力,成為配角。
我們之前把CPU比做數學系教授,把GPU比做一年級本科生,那NPU就是CPU手下的在讀博士,無需手把手指導,就能快速的進行卷積運算和矩陣乘法運算。簡單來說就是:NPU成為提供算力輸出的主力,CPU和GPU退居輔助位置。
HW3.0平台上配備了兩顆FSD芯片,相互校對,相互冗餘,整個系統的算力就是144TOPS,是前一代HW 2.5的7倍多(20TOPS)。而憑藉顛覆性的架構設計,整個系統的功耗降低到了220W,功耗比則從0.067TOPS/W躍升至0.65TOPS/W。
FSD芯片讓特斯拉實現了芯片的“獨立自主”,此時離他們第一次購買Mobileye的產品只過去了短短5年。
而圍繞自動駕駛“四要素”,特斯拉的突破還在繼續。在2021年8月19日舉行的特斯拉AI Day上,除了人工智能總監Andrej Karpathy詳細闡述了基於視覺的神經網絡方案外,「計算平台」的突破成果也被展示出來,即特斯拉Dojo ExaPOD超級計算機。
Dojo ExaPOD由120個訓練模塊組成,每一個訓練模塊包含25塊特斯拉自研的D1芯片,總芯片數量達到了3000塊。D1芯片由台積電代工,採用7nm工藝,3000塊D1芯片疊加起來,直接讓Dojo以1.1 EFLOP的算力成為全球第五大算力規模的計算機。
 Dojo負責人Ganesh展示D1芯片,2021 AI Day
Dojo負責人Ganesh展示D1芯片,2021 AI Day
客觀評價,特斯拉畢竟是芯片領域的“新兵”,自研的芯片未必真的能媲美半導體巨頭,尤其是研發Dojo的成本比從英偉達直接買還要高。但考慮到特斯拉在幾乎時零基礎的情況下擠進了AI芯片第一梯隊,這份成績單還是足夠優秀的。
自此“自己動手,豐衣足食”,馬斯克對“四要素”的全鏈條掌控已經基本成型:
採用“純視覺方案”,核心算法基於深度神經網絡,在雲端由自己研發的Dojo超級計算機進行訓練,終端上自研的FSD芯片實時處理周圍環境數據,識別對象,預測行為,作出判斷,最後控制車輛動作,實現自動或半自動的“智能駕駛”。
為了加快自動駕駛的成熟速度,特斯拉在2020年10月啟動了FSD Beta的內測,面向的人群是一小部分願意把現實世界的行駛數據上傳給特斯拉來進行算法訓練和乾山的車主,而採集到的大量數據則會被餵給“雲端”的超級計算機來訓練模型和算法。
大量花了15000美元選配FSD服務的車主願意“自帶乾糧”給特斯拉充當“無人駕駛測試員”。2021年有2000多位車主參加了FSD Beta的內測;到2022年10月,這一數字飆升到了16萬;之後FSD Beta向北美地區全部開放,參與車主數量達到36萬。
 一名北美用戶正在使用FSD Beta,2022年
一名北美用戶正在使用FSD Beta,2022年
海量的數據投餵給日夜不停的超級計算機,帶來了自動駕駛的快速迭代。在2022年的AI Day上,特斯拉給出了一組數據:採集了480萬段數據,訓練了75778個神經網絡模型,其中有281個模型被實際用到特斯拉車上,推動FSD迭代了35個版本。
在披露這些數據前,馬斯克在開場白中講了一句話:基本上我認為,我們是人工智能在現實世界應用的無可爭議的領導者。
在ChatGPT火爆全球之後,這句話的可信度顯然打了不小的折扣。不過從2013年開始,特斯拉用了9年就吃透了人工智能的玩法,把AI搬上了數百萬台汽車,從算法、芯片再到計算平台全部實現自研,基本上領先所有的競爭對手,包括賣鏟子的英偉達。

馬斯克曾在微博稱特斯拉的AI實力被“低估”
當然,爭議始終伴隨著特斯拉。一方面,L4級的自動駕駛難度過高,大量廠商被卡在L2級~L3級這一地帶,即使特斯拉的FSD更新到v11版本,也仍然沒有擺脫“Beta”的後綴。在今年2月初,特斯拉更是宣布召回了36萬輛配備有FSD的汽車。
另一方面,特斯拉在營銷「自動駕駛」時的激進也少不了被口誅筆伐,馬斯克在推銷自家的自動駕駛技術方面不僅接地氣,而且接地府,吹牛、撕逼、PUA同行、期貨當現貨賣……無所不用其極。這種「表演」,有時候反而會讓人忽略了特斯拉的真正實力。
但眾所周知,特斯拉汽車在全球的熱賣,目前跟自動駕駛關係不是很大,尤其在中國,FSD開通率只有可憐的2%不到,全球範圍也只有10%~20%的水平。用戶選擇特斯拉汽車,更多的是因為品牌光環以及其在設計、製造、價格方面的優勢。
而特斯拉之所以持續投資人工智能,除了本身自動駕駛是一大營銷賣點外,還有一個原因:人工智能將是未來20年人類最重要的科技主線。
電動車產業雖然坐擁風口,但本質上仍然是製造業,效率曲線的改善會逐步趨緩。比如,動力電池的容量不會每年翻一番,一體化壓鑄的成本也不會每年下降50%,特斯拉在製造環節的優勢在渡過紅利期之後,遲早會被更卷的廠商追上。
但人工智能卻像火箭一樣在加速,並極有可能引爆一場像工業革命一樣的浪潮。如果特斯拉能夠從一家單純的汽車公司,變成一家擁有兩大落地場景(汽車和機器人)的人工智能公司,那麼今天投入的每一分錢,未來都將是跟競爭者的巨大優勢。
不過特斯拉在AI領域的狂飆,常常被一些戲謔性的場景所沖淡。2022年10月,被業界期待已久的Tesla Bot發布,但三名吃力抬著機器人上台的壯漢讓場面一度尷尬。兩個月後ChatGPT引爆全球,Tesla Bot徹底成為全球AI狂歡的背景板。

被工作人員“抬”上來的Tesla Bot
OpenAI用ChatGPT告訴我們:人工智能的發展總是呈現非線性的,一旦“奇點”臨近,爆發就會以難以想像的速度來臨。誰都不敢妄言特斯拉測試兩年多的FSD Beta不會在不遠的未來取得突破,這台裝了FSD芯片的機器人,也是一樣。
從這角度出發,特斯拉這台電線裸露的Bot,是不是越看越像《复聯2》的奧創或者施瓦辛格?
05尾聲:向老鄉預警,給矽基帶路
在2003年上映的電影《終結者3》裡,毀滅人類的超級計算機——天網的算力是60 TFlops。
二十年過去了,遊戲玩家手上的一張RTX 4090顯卡,就能達到100 TFlops,相當於1.67個天網;一張英偉達A100的算力(FP16)能夠達到156TFlops,相當於2.6個天網,而ChatGPT背後的數據中心裡,至少有2萬張英偉達A100和性能更強的H100。

《終結者3》裡啟動的SkyNet,2000年
人類在科技樹的某一個枝椏上「狂飆」時,想像力可能都無法跟不上步伐。現在是2023年,Google發表那篇闡述“注意力機制”的論文,距今只有5年;AlphaGo擊敗李世石,距今只有7年;而OpenAI這家公司成立,距今也才不到8年時間。
特斯拉研發無人駕駛的時間線,跟人工智能這門科學在近10年的突飛猛進密不可分的,而人工智能的演進速度會越來越快。OpenAI創始人Sam Altman剛提了一個新的理論:新的摩爾定律將會開啟,宇宙中的智能生命每隔18個月將會翻一倍。

在特斯拉投資者日公佈的Master Plan 3(宏願3)中,馬斯克預期特斯拉未來每年能夠生產2000萬輛車——這也意味著,每年把2000萬個擁有極強算力的矽基生命送到碳基人類的千家萬戶,同時這些終端的“智力”正在晝夜不停地進化。
電影《教父》里柯里昂說過說:離自己的朋友要近,離自己的敵人要更近。馬斯克顯然明白無法阻擋洪流,索性為矽基的崛起助力。至於這種“助力”,究竟是碳基通往自由之路上的磚石,還是絞刑架上的繩索,馬斯克可能管不了那麼多了。
一邊向碳基老鄉預警,一邊給矽基皇軍帶路,馬老師已經做出了自己的選擇。我們呢?
全文完,總長1.2萬字,感謝您的耐心閱讀。
本文撰寫得到了ChatGPT的大力協助,特此鞠躬。









