


隨著OpenAI 推出ChatGPT 在人工智能領域掀起的千層浪,生成式AI 開始被普羅大眾所熟知。《日本經濟新聞》在此前報導中指出,全球100 多家大規模生成式AI 企業總市值達480 億美元,約為2020 年的6 倍,OpenAI 的確引領了市場對生成式AI 企業的投資熱潮。
實際上,除了OpenAI,AI 的發展浪潮中還有Jasper、DeepMind、Stability、Cohere 等競爭者。5 月3 日,《紐約時報》報導稱,兩名知情人士透露Cohere 已獲2.5 億美元融資,估值約20 億美元,投資者包括互聯網軟件巨頭Salesforce、芯片製造商Nvidia、多倫多風投公司Inovia Capital 和矽谷公司Index Ventures。這是自2022 年ChatGPT 發布後在生成式AI 領域的最新重大投資。而此前,Cohere 籌集的總資金已達1.7 億美元,包括2022 年由Tiger Global 領投的1.25 億美元B 輪融資。
「百舸爭流,奮楫者先;千帆競發,勇進者勝」。作為加拿大的一家初創企業,Cohere 何以突出重圍,斬獲眾多投資者的青睞?了解該企業的發展歷程、其產品區別於ChatGPT 的獨特優勢後,相信我們會對投融資市場風向的選擇理由與生成式AI 的發展動向有所理解。
一篇著名的論文
創立於2019 年的Cohere 是一家自然語言處理(NLP) 公司,基於大型NLP 模型為外界提供API 服務,從而提高計算機理解和生成文本、閱讀和寫作的能力。該公司由艾丹·戈麥斯(Aidan Gomez) 與兩個朋友Nick Frosst 和Ivan Zhang 一起創辦,它的總部位於加拿大多倫多,在美國舊金山、英國倫敦均設有辦事處。自合作以來,他們組建了一支約135 人的團隊,目前還在繼續擴建以更好的提供相關API 服務。

兩位聯合創始人Aidan Gomez 和Nick Frosst 曾擔任過谷歌研究員,其中Aidan Gomez 是大名鼎鼎的《Attention Is All You Need》論文的作者之一。該論文提出了一種新的、被譽為ChatGPT 的「祖師爺」的網絡架構「Transformer」,ChatGPT 通過Transformer 模型進行了序列建模,並通過自回歸方式進行訓練,使得大語言模型能夠根據前文內容和當前輸入,生成符合語法規則和語義邏輯的擬人化內容,這使得國內外都掀起了一波未平一波又起的大規模語言模型訓練的熱潮。
Cohere 提供了與ChatGPT 類似的產品,目前主要包括:搜索文本(多語言嵌入、神經搜索、搜索排名)、分類文本和生成文本三大類產品,幫助企業快速部署對話式AI 聊天機器人、生成式搜索引擎、文本摘要總結、增強向量搜索等,是為數不多在技術層面具備與OpenAI 進行競爭的AI 企業之一,這也是其受到資本市場青睞的重要原因之一。
Cohere 曾在2021 年9 月獲得4000 萬美元A 輪融資;2022 年2 月獲得1.25 億美元B 輪融資,投資者包括老虎環球基金、「AI 教父」 Geoffrey Hinton、斯坦福大學教授李飛飛、深度學習專家Pieter Abbeel 等。在2022 年10 月,Cohere 便開始與穀歌、Salesforce、Nvidia 進行融資談判,如今,Cohere 獲得巨額融資將繼續與OpenAI 展開激烈競爭,繼續加快類似ChatGPT 產品的技術創新和更新迭代。
資本為何青睞?
實際上,在OpenAI 發布GPT-4 之後的一段時間內,大部分人都將目光聚焦於AI 大模型,包括Anthropic、 AI21、 Cohere 和Character.AI 在內的眾多資金充足的初創公司都在投入大量資源來構建更大的算法和模型,以期待努力趕上OpenAI 的技術。
但就在AI 競賽如火如荼開展之時,OpenAI 的首席執行官Sam Altman 卻表示巨型AI 模型的時代已結束,「未來新一步的進化,將不會來自於巨型模型」。那同屬該領域的Cohere 又為何會獲得資本的青睞呢?
Cohere AI 将其模型分为两类:生成模型和嵌入模型。生成模型通过对互联网上大量的数据进行训练,而嵌入模型是多语言支持的,可以支持超过 109 种语言。Cohere 的模型有不同的规格,公司的指令模型每周都在进步,而同类领域的其他提供商通常要几个月或甚至一年才会发布重要的模型更新。
儘管Cohere AI 與穀歌合作獲取其硬件能力,但其並不僅限於Google Cloud。例如,Cohere 在AWS SageMaker 上運營,併計劃在其他雲服務提供商上提供服務。Cohere AI 的方法非常開放,並以客戶為中心,他們通過在任何云供應商上運行以使客戶獲得最佳體驗和服務。
相較於GPT-4,Cohere AI 尚未採用多模態方法。Cohere AI 的高級副總裁Saurabh Baji 表示,「我認為圖像和視頻非常令人興奮。但從商業角度來看,這也是一個不同的問題。我們並不關注AGI,而是專注於客戶實際面臨的問題。很多客戶的需求都非常以語言為中心。」
從AI 競爭格局的角度來看,Cohere AI 和OpenAI 都是目前AI 領域的重要參與者。雖然兩家公司都專注於大型語言模型,但它們的重點和方法略有不同。OpenAI 在一系列領域都有所涉獵,包括自然語言處理、計算機視覺和強化學習等。此外,OpenAI 也吸引了大量的資本,其中包括像微軟、谷歌和亞馬遜這樣的科技巨頭。

相比之下,Cohere AI 專注於提供易於使用和部署的大型語言模型,為企業客戶提供更好的商業解決方案。儘管Cohere AI 在規模和影響力上與OpenAI 存在一定的差距,但其在語言模型方面的專注度和靈活性使其成為一個非常有前途的公司。
另外,在資本方面,Cohere AI 也獲得了很多青睞。除了幾個知名風險投資公司的支持,該公司還獲得了加拿大政府和Google 等科技巨頭的支持。這些資金的注入有助於Cohere AI 繼續擴展其業務和規模,並在AI 市場上取得更大的份額。
總的來說,雖然Cohere AI 和OpenAI 在AI 競爭格局中處於不同的位置,但它們都是這個領域中非常有前途的公司。Cohere AI 在語言模型方面的專注度和靈活性使其成為一個與OpenAI 進行競爭的關鍵因素之一,而資本的支持也給了Cohere AI 更多的機會來發揮其潛力,並在市場上取得更大的份額。
實用角度看大語言模型
大語言模型(Large Language Models,簡稱LLMs)是一類基於深度學習技術的自然語言處理(NLP)模型,它們具有大量的參數,並能夠理解和生成人類語言。這類模型通常採用神經網絡架構,尤其是Transformer 架構。
近期,一篇綜述論文《在實踐中利用大模型的力量》在AI 學術圈爆火,而其中一張名為「大預言模型進化樹」的圖片引起了不小的轟動,其梳理了2018 年到2023 年的大預言模型代表作。
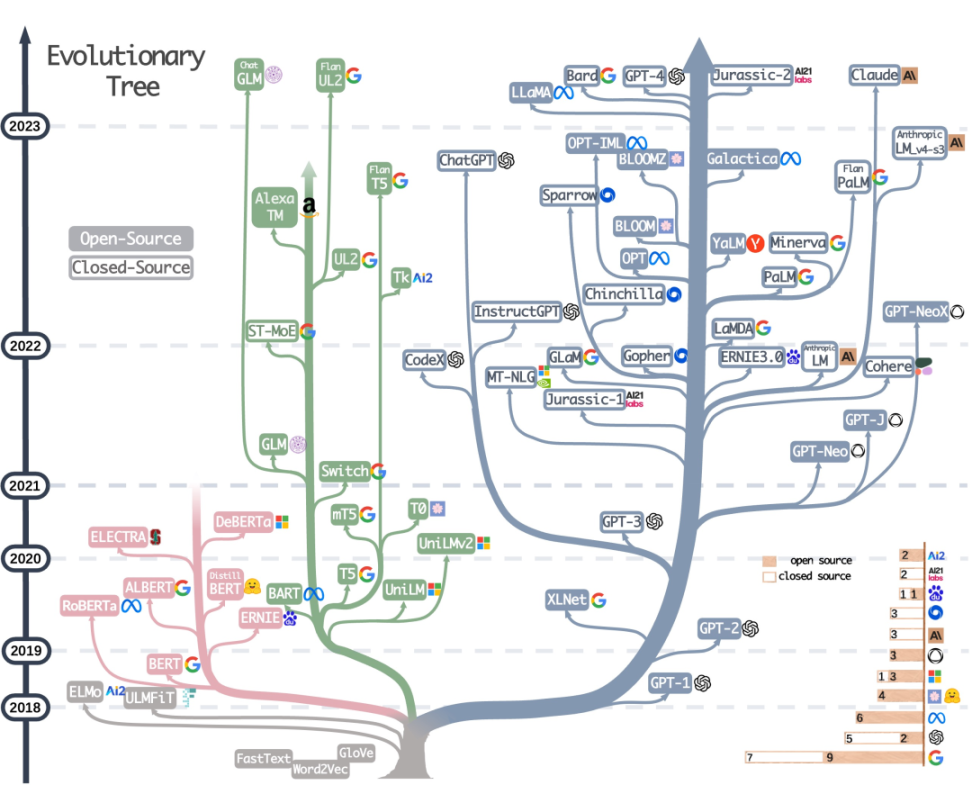
相較於Open AI 不斷深耕至今走向AI 的前沿,曾經頗具影響力的谷歌BERT 似乎從一開始就走向了「岔路」。當我們以年為單位看LLM 發展史的時候,忍不住唏噓「在大模型沒有成功之前,一切都是場賭局」。
大語言模型發展進化史
2017 年的時候,谷歌研究員在《Attention is all you need》一文中介紹了Transformer 架構——這也是目前最常用到的架構之一,是BERT、GPT 等預訓練模型的基礎。時至今日,Transformer 架構仍是GPT 模型的基礎架構。
Transformer 架構的提出和預訓練的方法將大語言模型推向了新的階段——以穀歌為首的科技大公司在2017 年後聚焦於研發能夠處理多種自然語言任務的大模型。
2018 年6 月,OpenAI 採用Transformer 架構發布了它們的模型——GPT-1。緊接著,谷歌正式向世界介紹了全新預訓練模型——BERT。

時間來到2019 年,微軟宣布與OpenAI 達成10 億美金的合作。次年9 月,OpenAI 授權微軟使用GPT-3 模型,微軟成為全球首個享用GPT-3 能力的公司。
科技巨頭Meta 當然也不甘示弱,於2022 年推出有著「開源版本的GPT-3」之稱的OPT,並於今年推出能在單個GPU 上運行的大語言模型LLaMA。
如今GPT-4 也已發布,更強的文本生成能力與詳細的邏輯判斷能力讓OpenAI 在四年內快速崛起,並成功「破圈」。
Cohere 的聯合創始人Nick Frosst 對Altman 認為大模型不會永遠奏效的觀點也是表示認同的,他表示「有很多方法可以讓Transformer 變得更好、更有用,而且很多方法並不涉及向模型添加參數」。Frosst 還說,新的AI 模型設計或架構,以及基於人類反饋的進一步優化,將會是許多人工智能研究人員已經在探索和有前途的方向。
一些有前景的LLM 用例
利用LLM 大模型可以做許多「很酷」的事情,但我們必須承認,基於人類實際需求的創新發展方向才是最根本的邏輯,所以「實用主義」是我們考量LLM 應用的重要指標。
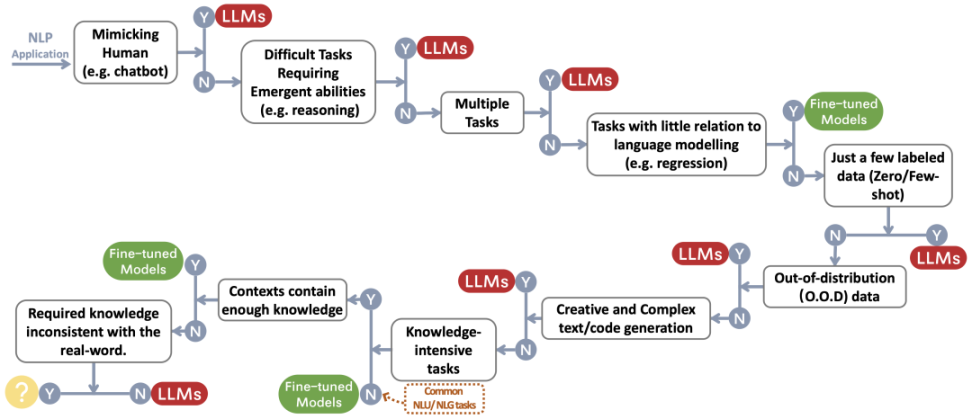
對於到底是選擇只經過預訓練的大模型LLM,還是在此基礎上經過特定數據集微調後的較小模型問題,《在實踐中利用大模型的力量》這篇論文給出的答案是具體情況具體分析,我們可以參照這張決策流程思維導圖來獲得一些啟示。
各種基於LLM 構建的應用程序在不斷刷新我們的認知,計算機科學家Chip Huyen 在其文章《為生產構建LLM 應用程序》中為我們提供了一些有前景的LLM 用例:
- 人工智能助手:針對不同用戶群體來構建不同的任務,比如安排日程、做筆記、預訂航班、購物等。但是,最終目標是打造一個可以幫助你做任何事情的智能助手。
- 聊天機器人:聊天機器人在API 方麵類似於人工智能助手。如果說人工智能助手的目標是完成用戶交給它的任務,那麼聊天機器人的目標更多的是成為一個伴侶。例如,你可以讓聊天機器人像名人、電影角色、作家等一樣說話。

- 學習:ChatGPT 不僅可以生成問題,還可以評估學生輸入的答案是否正確,以及對論文進行評分和反饋。同時,它也很擅長在同一個辯論話題上採取不同的立場,可以成為學生很好的辯論夥伴。
- 搜索引擎優化:如今,許多公司都依賴於創造大量內容,希望在谷歌上排名靠前。但在未來,搜索引擎優化可能會變得更像一場貓捉老鼠的遊戲:搜索引擎會想出新的算法來檢測人工智能生成的內容,而公司則會更好地繞過這些算法。人們可能也會減少對搜索的依賴,而更多地依賴品牌(例如,只相信某些人或公司創造的內容)。
除此之外,大語言模型可以幫助生命科學研究人員更好地理解蛋白質、分子、DNA 和RNA,幫助信用卡公司進行異常檢測和欺詐分析以保護消費者,幫助法律團隊進行法律釋義和抄寫等。
在未來的模型面前,或許現在我們看到的大模型只是螻蟻。但我們可以期待,未來更加強大的語言模型將會更徹底改變人們的生活方式。
現在,我們可以看到越來越多的企業湧入AI 的洪流,個體也不可避免地主動參與或者被席捲進去,我們永遠不知道明天會發生什麼。未來的另一個五年又會有多少大語言模型出現,誰又將沖在行業最前端呢?讓我們拭目以待。









